本文word2vec原理参考:NLP扎实基础1:Word2vec模型Skip-Gram Pytorch复现
1. Skip-Gram与CBOW的区别
CBOW(Continuous Bag-of-Words)和 Skip-Gram(Continuous Skip-gram Model)是Mikolov设计的两种用于计算连续的、分布式的词向量的模型,作者用一副非常概括、简洁的示意图来表明这两种模型的区别,这也是该论文中唯一的图。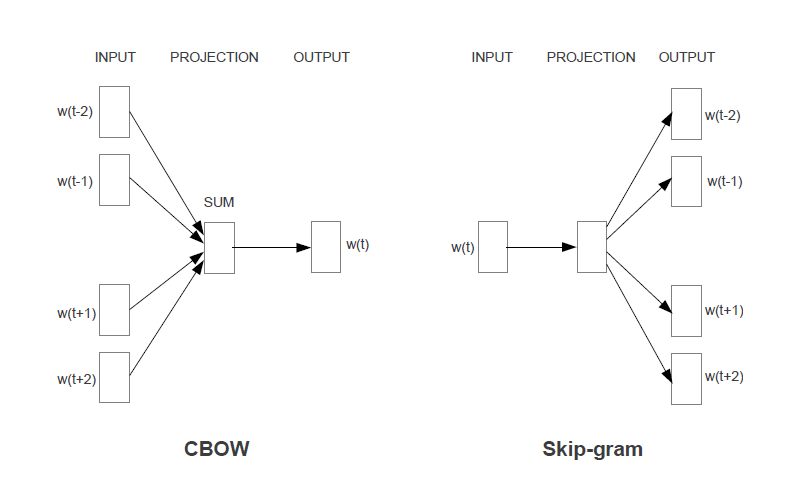
这幅图很有对称的美,但是也很有迷惑性,在没有深入理解代码前,是很难想到作者真正实现的方法与思想。CBOW模型输入是滑动窗口内背景词的平均,输出是中心词是词典中某个词的对数softmax。Skip-Gram模型的输入相对而言就比较复杂,分别是中心词,背景词以及随机采样得到的噪声词,而后两者也被称为正例和负例,输出则是中心词与负例词向量的内积减去与正例词的内积,这也就是优化的目标。
2. 词向量表示的目标
我们都知道分布式词向量的提出是神经概率语言模型的副产物,后者致力于对一个句子的概率做出预测,在该论文《A Neural Probabilistic Language Model》中举了两个例子:
- The cat is walking in the bedroom
- A dog was running in a room
第一个句子是在语料库中的,那么神经概率语言模型应该会得到一个比较大的概率值,同时第二个句子中的词都是与第一个句子中的词一一对应并且语义上相似的,也应该有一个较大的概率,然后在论文中写到“In the proposed model, it will so generalize because “similar” words should have a similar feature vector”,也就是说语义相似的词应该要有相近的特征向量表示,这样上面两个句子才能有相近的概率。
3. 殊途同归,尝试解释
Skip-Gram与CBOW模型继承了这样的目标,但是实现的方法却不一样。Mikolov提出了这两种模型,并设计了测试的方法,但是论文中并没有提到设计的动机,对这两种模型进行解释有一些讨论。
首先是CBOW模型,模型的输入是背景词的平均,有一部分人是这样解释的:“句子中挨得越近的词越相似,离的越远的词越不同”,这似乎是对平均操作的分析结果。这样的想法首先违背了一般的常识,一个句子中的各个单词有不同的作用,词性也基本都不同,而且语义相似的词在一个句子里重复出现也显得累赘。《NLP扎实基础1:Word2vec模型Skip-Gram Pytorch复现》举了一组例子:“我/爱/跑步”,“我/爱/撸串”,“我/爱/烤串”,并说明虽然“我”和“爱”、“撸串”没有明显联系,但是这三个句子里“撸串”、“烤串”、“跑步”就有一定的关联,当采用CBOW或Skip-Gram训练时,这三个词会越来越近。当语料足够大的时候,“撸串”和“烤串”同时出现在类似的句子中的概率是非常大的,但是“跑步”出现的句子场景就不同了,因此就把“撸串”、“烤串”越训练越接近,而“跑步”就稍稍疏远。这个说明与神经概率语言模型中的例子有相似的思想。但是结合《NLP扎实基础2:Word2vec模型CBOW Pytorch复现》具体实现的代码就会发现存在一些问题,如果我们认为相似的词出现在相似的语境,词与词的差别会体现在语境里(这里的语境特指滑动窗口内的背景词),那么对于两个非常相似的词而言,他们有非常一致的语境,但是在词典中的位置确不一样,由于word2vec模型输出的是对数softmax,这时即使语境是相似的,模型输出也是相似的,但是和实际中心词还是会存在较大差距。
对于Skip-Gram模型来说,优化的目标是:中心词与背景词的内积要小,与噪声词的内积要大,乍一看似乎是因为“句子中挨得越近的词越相似,离的越远的词越不同”,但我认为其实是